
1. 뼈대만들기
import numpy
import scipy.special
class neuralNetwork:
#신경망 초기화 하기
def __init__(self, inputnodes, hiddennodes, outputnodes, leaningrate):
pass
#신경망 학습시키기
def train(self, inputs_list, targets_list):
pass
#신경망에 질의하기
def query(self,inputs_list):
pass- 초기화 : 입력, 히든, 출력 노드 수 설정
- 학습 : 학습 데이터를 통해 학습하고 이에 따라 가중치를 업데이트
- 질의 : 입력을 받아 연산한 후 출력 노드에서 답을 전달
2. 신경망 초기화하기
import numpy
import scipy.special
class neuralNetwork:
def __init__(self, inputnodes, hiddennodes, outputnodes, leaningrate):
# 입력 , 히든, 출력 계층의 노드 개수 설정
self.inodes = inputnodes
self.hnodes = hiddennodes
self.onodes = outputnodes
# 학습률
self.lr = leaningrate위 코드를 클래스 정의부분에 추가하였고,
각각의 계층에 3개의 노드를 가지며, 0.3 학습률을 가지는 작은 신경망 객체를 하나 만들어봅니다.
# 입력 , 히든, 출력 노드의 수
input_nodes = 3
hidden_nodes = 3
output_nodes = 3
# 학습률을 0.3으로 정의
learning_rate = 0.3
# 신경망의 인스턴스를 생성
n = neuralNetwork(input_nodes,hidden_nodes,output_nodes,learning_rate)import numpy
import scipy.special
class neuralNetwork:
def __init__(self, inputnodes, hiddennodes, outputnodes, leaningrate):
self.inodes = inputnodes
self.hnodes = hiddennodes
self.onodes = outputnodes
self.lr = leaningrate
pass
def train(self, inputs_list, targets_list):
pass
def query(self,inputs_list):
pass3. 신경망의 핵심인 가중치
노드와의 연결 노드를 생성하는 작업을 생성해봅시다.
신경망에서 가장 중요한 부분은 바로 연결 노드의 가중치 입니다.
가중치는 전파 시 전달되는 신호와 역전파 시 오차를 계산하는데 쓰이며, 이를 통해 신경망 을 개선하는 역할을 수행한다.
가중치는 행렬로 간결하게 표현될 수 있다는 사실을 알 고 있다.
- (히든 노드 * 입력 노드) 의 크기를 가지는 입력 계층과 히든 계층 사이의 가중치의 행렬
- (출력 노드 * 히든 노드) 의 크기를 가지는 히든 계층과 출력 계층 사이의 가중치의 행렬
첫번째 행렬의 크기를 ( 입력 노드 * 히든 노드) 가 아니라 (히든 노드 * 입력 노드) 로 표기한 이유에 대해서는 앞에서 관행적으로 이렇게 표기한다고 했던 것을 떠올리자
numpy.random.rand 의 경우 1~0 까지 랜덤으로 생성뙨다, 가중치는 음수일수도 있기때문에 -0.5 ~0.5 사이의 값을 갖도록 변경
이제 파이썬프로그램에서 가중치 행렬을 초기화할 준비가 되었다.
가중치는 신경망에서 본질적인 부분이므로 함수가 호출되었을 때 사용되었다가 사라지는 것이 아니라 신명망의 처음부터 끝까지 함께 존재
# 가중치 행렬 wih & who
# 배열 내 가중치는 w_i_h 로 표기 노드 i 에서 다음 계층의 노드 j 로 연결됨을 의미
# w11 w21
# w12 w22 등
self.wih = (numpy.random.rand(self.hnodes, self.inodes) -0.5)
self.who = (numpy.random.rand(self.onodes, self.hnodes) -0.5)신경망에 질의하기
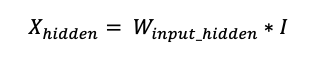
다행히 우리는 간단한 행렬의 형태로 표현하는 방법을 배웠다.
파이썬 같은 프로그래밍 언어가 행렬을 이해하고 몯느 계싼 사이의 유사성을 인식
hidden_inputs = numpy.dot(self.wih, inputs)정말 간단한다.
이제 은닉계층으로부터 나오는 신호를 구하려면 시그모이드 함수를 적용하기만하면 됩니다.

시그모이드 함수가 파이썬 라이브러리에 이미 정의만 되어있다면 아주 쉬운 작업이다.
import scipy.special
# 활성화 함수로 시그모이드 함수를 이용
self.activation_function = lambda x: scipy.special.expit(x)이코드는 왜 이리 복잡해 보일까?
람다 (lambda) 가 뭘까요?
그저 함수하나 생성한 것 뿐인데 다만 간결하게 적어준것 뿐입니다.
일반적으로 def() 에 의한 함수 정의 대신에 마법과 같은 람다를 사용해 빠르고 쉽게 함수를 생선한 것이다.
여기에서 람다 함수는 x 를 매개변수로 전달 받아 시그모이드 함수인 scipy.special.expit(x) 를 반환하는 역할을 합니다.
람다에 의해 생성되는 함수는 이름이 없기 때문에 익명함수 라고도 합니다.
우리는 이 함수를 self.activation_function에 할당했습니다.
결론적으로 함수를 사용할 필요가 있으면, self.activation_function()을 호출하면 됩니다.
#은닉 계층에서 나가는 신호를 계산
hidden_outputs = self.activation_function(hidden_inputs)이제 은닉 계층의 노드로부터 나가는 신호들을 hidden_outputs 라는 이름의 행렬에 존재
지금까지는 가운데 위치하는 은닉계층을 봤는데 이제 최종적으로 출력계층을 살펴볼 차례
은닉계층과 최종 출력 계층 노드 사이에 차이점은 없기때문에 과정을 같다.
# 은닉 계층으로 들어오는 신호를 계산
hidden_inputs = numpy.dot(self.wih ,inputs)
# 은닉 계층에서 나가는 신호를 계산
hidden_outputs = self.activation_function(hidden_inputs)
# 최종 출력 계층으로 들어오는 신호를 계산
final_inputs = numpy.dot(self.who, hidden_outputs)
# 최종 출력 계층에서 나가는 신호를 계산
final_outputs = self.activation_function(final_inputs)주석을 제외하면 은닉 계층 두줄과 출력 계층 두줄 도합 네줄의 코드로 우리가 필요로하는 모든 연산을 처리한 것입니다.
지금까지 코드
class neuralNetwork:
#신경망 초기화 하기
def __init__(self, inputnodes, hiddennodes, outputnodes, leaningrate):
self.inodes = inputnodes
self.hnodes = hiddennodes
self.onodes = outputnodes
#가중치 행렬 wih & who
#배열 내 가중치는 w_i_j 로 표기, 노드 i 에서 다음 계층의 노드 j 로 연결됨을 의미
# w11 , w21
# w12 , w22 등
self.wih = (numpy.random.rand(self.hnodes, self.inodes) -0.5)
self.who = (numpy.random.rand(self.onodes, self.hnodes) -0.5)
#학습률
self.lr = leaningrate
#활성화 함수로는 시그모이드 함수를 이용
self.activation_function = lambda x : scipy.special.expit(x)
pass
# 신경망 학습 시키기
def train():
pass
# 신경망에 질의하기
def query(self, inputs_list):
# 입력 리스트를 2차원 행렬로 변환
inputs = numpy.array(inputs_list, ndmin=2).T
# 은닉 계층으로 들어오는 신호를 계산
hidden_inputs = numpy.dot(self.wih, inputs)
# 은닉 계층에서 나가는 신호를 계산
hidden_outputs = self.activation_function(hidden_inputs)
# 최종 출력 계층으로 들어오는 신호를 계산
final_inputs = numpy.dot(self.who, hidden_outputs)
# 최종 출력 계층에서 나가는 신호를 계산
final_outputs = self.activation_function(final_inputs)
return final_outputs
pass단지 클래스일 뿐이므로 코드의 시작 부분에서는 numpy 와 scipy 모듈을 불러오는 코드 (import numpy 및 import scipy.special) 을 넣어야 합니다.
또한 query() 함수는 매개변수로 input_list 만 받는다는 점도 기억
이제 남은 것은 학습
학습에는 두가지 단계가 있다.
첫번째 단계는 query() 함수와 마찬가지로 출력값을 계산하는 단계
두번째 단계는 가중치가 어떻게 업데이트 되어야하는지 알려주기 위해 오차를 역전파하는 단계
class neuralNetwork:
#신경망 초기화 하기
def __init__(self, inputnodes, hiddennodes, outputnodes, leaningrate):
self.inodes = inputnodes
self.hnodes = hiddennodes
self.onodes = outputnodes
#가중치 행렬 wih & who
#배열 내 가중치는 w_i_j 로 표기, 노드 i 에서 다음 계층의 노드 j 로 연결됨을 의미
# w11 , w21
# w12 , w22 등
self.wih = (numpy.random.rand(self.hnodes, self.inodes) -0.5)
self.who = (numpy.random.rand(self.onodes, self.hnodes) -0.5)
#학습률
self.lr = leaningrate
#활성화 함수로는 시그모이드 함수를 이용
self.activation_function = lambda x : scipy.special.expit(x)
pass
# 신경망 학습 시키기
def train():
# 입력 리스트를 2차원의 행렬로 변환
inputs = numpy.array(inputs_list, ndmin=2).T
targets = numpy.array(targets_list, ndmin=2).T
# 은닉 계층으로 들어오는 신호를 계산
hidden_inputs = numpy.dot(self.wih, inputs)
# 은닉 계층에서 나가는 신호를 계산
hidden_outputs = self.activation_function(hidden_inputs)
# 최종 출력 계층으로 들어오는 신호를 계산
final_inputs = numpy.dot(self.who , hidden_outputs)
# 최종 출력 계층에서 나가는 신호를 계산
final_outputs = self.activation_function(final_inputs)
pass
# 신경망에 질의하기
def query(self, inputs_list):
# 입력 리스트를 2차원 행렬로 변환
inputs = numpy.array(inputs_list, ndmin=2).T
# 은닉 계층으로 들어오는 신호를 계산
hidden_inputs = numpy.dot(self.wih, inputs)
# 은닉 계층에서 나가는 신호를 계산
hidden_outputs = self.activation_function(hidden_inputs)
# 최종 출력 계층으로 들어오는 신호를 계산
final_inputs = numpy.dot(self.who, hidden_outputs)
# 최종 출력 계층에서 나가는 신호를 계산
final_outputs = self.activation_function(final_inputs)
return final_outputs
pass입력 계층으로부터 신호를 최종 출력 계층까지 전파하는 과정은 query() 함수와 동일하므로 그 내용은 거의 동일합니다.
다만 한가지 차이가 있다.
함수명 부분을 자세히 보기바랍니다.
targets_list라는 매개변수가 추가로 존재한다.
이 매개변수가 없이는 우리는 신경망을 제대로 학습시킬 수 없다.
def train(self, inputs_list, targets_list)앞에서 inputs_list 를 numpy 배열로 변환했던것과 동일한 방법으로 targets_list를 변환해줍니다.
targets = numpy.array(targets_list, ndmin=2).T이제 계산 값과 실제 값 간의 오차에 기반해 신경망의 동작에서 핵심이 되는 가중치를 업데이트할 준비가 거의 되었습니다.
단계별로 나누어 차근차근 봅시다.
우선 오차를 계산해야합니다. 오차는 학습데이터에 의해 제공되는 실제 값과 우리가 계산한 결과 값간의 차이로 정의
결국 오차는 (실제 값 행렬 - 계산 값 행렬) 이라는 연산의 결과 값이 됩니다.
이 연산은 원소 간 연산입니다.
이를 파이썬으로 구현하면 다음과 같이 간단하게 가능합니다.
다시한번 행렬의 위력을 실감할 수 있다.
#오차는 (실제 값 - 계산 값)
output_errors = targets - final_outputs우리는 은닉 계층의 노드들에 대해 역전파된 오차도 구할 수 있습니다.
앞에서 연결 노드의 가중치에 따라 오차를 나눠 전달하고 각각 은닉계층의 노드에 대해 이를 재조합했던 작업을 상기
이를 행렬로 다음과 같이 처리

이를 코드로 표현하는 것 역시 매우 간단합니다. 바로 파이썬의 numpy 를 활용한 행렬 곱 연산 능력 덕분이죠
# 은닉 계층의 오차는 가중치에 의해 나뉜 출력 계층의 오차들을 재조합해 계산
hidden_errors = numpy.dot(self.who.T, output_errors)이로써 우리는 각각의 계층에서 가중치를 업데이트하기 위해 필요한 모든 것을 갖추었습니다.
은닉 계층과 최종 계층 간의 가중치는 output_errors 를 이용하면 되고,
입력 계층과 은닉 계층간의 가중치는 방금 구한 hidden_errors 를 이용하면 되는 것이다.
앞에서 노드 j 와 다음 계층의 노드 k 간의 가중치 업데이트를 행렬로 표현한 바있습니다.
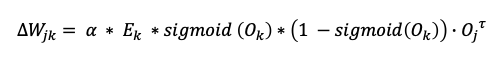
알파는 학습률을 의미하며 , 시그모이드는 활성화 함수 , * 는 원소 간 곱을 의미 , 점(.) 은 행렬 곱을 의미합니다.
마지막 항인 직전 계층으로부터의 결과 값 행렬은 전치되어 있으므로 결과 값의 열이 결과 값의 행이 됩니다.
이를 파이썬 코드로 변환하는 것도 어렵지 않다.
# 은닉 계층과 출력 계층 간의 가중치 업데이트
self.who += self.lr * numpy.dot((output_errors * final_outputs * (1.0 - final_outputs)), numpy.transpose(hidden_outputs))# 은닉 계층과 출력 계층 간의 가중치 업데이트
self.who += self.lr * numpy.dot((output_errors * final_outputs * (1.0 - final_outputs)), numpy.transpose(hidden_outputs))
한 줄 치고는 좀 길지만 색상을 이용해 쉽도록 했습니다.
학습률은 self.lr
numpy.dot() 에 의한 행렬 곱 연산이 있는데, 이 행렬곱 연산에 들어가는 2개의 원소는 빨간색과 초록색으로 구분했다.
빨간색 부분은 오차와 다음 계층으로부터의 시그모이드에서 비롯되며
초록 색부분은 이전 계층으로부터의 결과 값을 전치한 것입니다.
앞에서 살펴본적 없으니 설명하자면 += 연산자의 의미는 연산자 앞에 있는 변수에 연산자 뒤에있는 부분을 더해서 할당
입력 계층과 은닉 계층 사이의 가중치에 대한 코드도 유사합ㄴ디ㅏ.
계층의 이름정도만 변경해주면 됩니다.
그 코드는 다음과 같다.
# 은닉 계층과 출력 계층 간의 가중치 업데이트
self.who += self.lr * numpy.dot((output_errors * final_outputs * (1.0 - final_outputs)), numpy.transpose(hidden_outputs))
# 입력 계층과 은닉 계층 간의 가중치 업데이트
self.wih += self.lr * numpy.dot((hidden_errors * hidden_outputs * (1.0 - hidden_outputs)), numpy.transpose(inputs))
이렇게 간단하게 구현가능
우리가 기존에 수행했던 엄청난 분량의 계산이 행렬을 이용한 접근 법과 신경망의 오차를 최소화하는 경사하강법을 통해 위와 같이 단지 몇줄의 코드로 손쉽게 구현된 것입니다.
우리는 파이썬의 강력한 기능과 그동안의 학습 내용을 기반으로 복잡하고 거대한 작업을 이처럼 간결하게 구현할 수 있었다.
완성된 신경망 코드
class neuralNetwork:
#신경망 초기화 하기
def __init__(self, inputnodes, hiddennodes, outputnodes, leaningrate):
self.inodes = inputnodes
self.hnodes = hiddennodes
self.onodes = outputnodes
#가중치 행렬 wih & who
#배열 내 가중치는 w_i_j 로 표기, 노드 i 에서 다음 계층의 노드 j 로 연결됨을 의미
# w11 , w21
# w12 , w22 등
self.wih = (numpy.random.rand(self.hnodes, self.inodes) -0.5)
self.who = (numpy.random.rand(self.onodes, self.hnodes) -0.5)
#학습률
self.lr = leaningrate
#활성화 함수로는 시그모이드 함수를 이용
self.activation_function = lambda x : scipy.special.expit(x)
pass
# 신경망 학습 시키기
def train():
# 입력 리스트를 2차원의 행렬로 변환
inputs = numpy.array(inputs_list, ndmin=2).T
targets = numpy.array(targets_list, ndmin=2).T
# 은닉 계층으로 들어오는 신호를 계산
hidden_inputs = numpy.dot(self.wih, inputs)
# 은닉 계층에서 나가는 신호를 계산
hidden_outputs = self.activation_function(hidden_inputs)
# 최종 출력 계층으로 들어오는 신호를 계산
final_inputs = numpy.dot(self.who , hidden_outputs)
# 최종 출력 계층에서 나가는 신호를 계산
final_outputs = self.activation_function(final_inputs)
# 출력 계층의 오차는 ( 실제 값 - 계산 값 )
output_errors = targets - final_outputs
# 은닉 계층의 오차는 가중치에 의해 나뉜 출력 계층의 오차들을 재조합해 계산
hidden_errors = numpy.dot(self.who.T, output_errors)
# 은닉 계층과 출력 계층 간의 가중치 업데이트
self.who += self.lr * numpy.dot((output_errors * final_outputs * (1.0-final_outputs)), numpy.transpose(hidden_outputs))
# 입력 계층과 은닉 계층간의 가중치 업데이트
self.wih += self.lr * numpy.dot((hidden_errors * hidden_outputs * (1.0-hidden_outputs)), numpy.transpose(inputs))
pass
# 신경망에 질의하기
def query(self, inputs_list):
# 입력 리스트를 2차원 행렬로 변환
inputs = numpy.array(inputs_list, ndmin=2).T
# 은닉 계층으로 들어오는 신호를 계산
hidden_inputs = numpy.dot(self.wih, inputs)
# 은닉 계층에서 나가는 신호를 계산
hidden_outputs = self.activation_function(hidden_inputs)
# 최종 출력 계층으로 들어오는 신호를 계산
final_inputs = numpy.dot(self.who, hidden_outputs)
# 최종 출력 계층에서 나가는 신호를 계산
final_outputs = self.activation_function(final_inputs)
return final_outputs
pass
수고많았습니다.
100% 내꺼로 이해해보자
'TensorFlow' 카테고리의 다른 글
| 신경망 , epochs ? (0) | 2022.04.15 |
|---|---|
| 신경망 첫걸음 , 06 MNIST 손글씨 데이터 인식하기 (0) | 2022.04.14 |
| 신경망 첫걸음, 05 가중치의 진짜 업데이트 (0) | 2022.04.01 |
| 신경망 첫걸음, 04 가중치 학습하기 (0) | 2022.03.31 |
| 신경망 첫걸음, 03 대자연의 컴퓨터, 뉴런 (0) | 2022.03.30 |